 Vonmo's Blog
Vonmo's Blog
Building distributed apps: first approximation

In the previous article we have addressed the theoretical basics or reactive architecture. Now it’s time to talk about data flows, ways of implementing reactive Erlang/Elixir systems, and message exchange patterns included in them:
- Request-response
- Request-Chunked Response
- Response with Request
- Publish-subscribe
- Inverted Publish-subscribe
- Task distribution
SOA, MSA and messaging
SOA and MSA are service architectures which define the rules of system development. Messaging, in its turn, provides us with primitives for their implementation.
I don’t want to advocate for any particular type of architecture. I’m all for using the practices which fully meet the needs of a certain project or business. Whatever paradigm we might choose, system components should be created with Unix-way in mind: components with minimal connectivity which are implementing different system entities. API methods perform basic actions on entities.
Messaging, as we can guess from the name, is a message broker. Its main aim is to receive and send messages. Also, it is responsible for message sending interfaces, creating of logical data communication channels, routing, balancing, and handling failures at the system level.
Messaging which is being developed does not try to compete with Rabbitmq or replace it. Among its main features are the following:
- Distributed nature. Exchanges can be created at any node of the cluster, as close as possible to the code which is exploiting them.
- Simplicity. Orientation towards usability and minimization of boilerplate code.
- Better performance. We are not trying to reproduce Rabbitmq functionality. We are just highlighting architectural and transport layers and embedding them into OTP, reducing the costs at the same time.
- Flexibility. Every service can integrate a number of exchange patterns.
- Fault tolerance embodied in design.
- Scalability. Messaging is growing together with the app. As the load increases, we can put some exchange points to separate machines.
Note. In terms of code organization, meta-projects aka umbrella projects are a good fit for complicated systems in Erlang/Elixir. All the project code is located in one repository — umbrella project. At the same time, microservices are isolated as much as possible and perform simple actions which are responsible for a separate entity. Under this approach, it’s easy to support the API of the whole system. You can also make changes and write unit or integrative tests effortlessly.
In service architectures components interact directly or via broker. From messaging point of view, every service has a number of life stages:
- Service initialization. At this stage initialization and start of the process with all its dependencies takes place.
- Creating an exchange. Service can use a static exchange, given in node config, or create exchanges dynamically.
- Service registration. Service must be registered on an exchange to be able to handle the requests.
- Normal working. In this mode service is processing user’s requests.
- Termination of the process. There are two possible ways of termination: a normal one and a crash one. In the first case, the service disconnects from the exchange and stops. In case of a crash, however, messaging performs one of the scenarios of handling the failures.
That might look a bit complicated, but actually it’s not that bad if you take a look at the code. Some code samples will be presented in this article a little later.
Exchanges
Exchange is an internal process of messaging service. It provides logic of interaction between different system components within defined message exchange pattern.
In all the examples below the components interact via exchanges whose combination creates messaging.
Message exchange patterns (MEPs)
Generally, all MEPs can be divided into two-way and one-way patterns. The former imply a response to the received message, the later do not. A classic case of a two-way MEP in client-server architecture is Request-response template. Let’s take a closer look at this one and its modifications.
Request-response or RPC
RPC is used when we need to get a response from another process. This process can be started at the same node or even be located on a different continent. Below you can see the diagram which demonstrates client-server interaction via messaging.
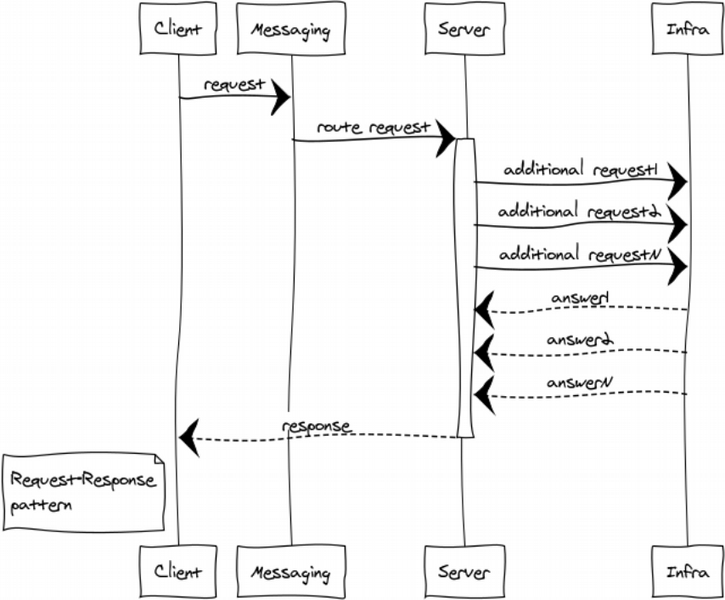
Since messaging is fully asynchronous, exchange for a client includes 2 stages:
-
Sending a request.
messaging:request( Exchange, ResponseMatchingTag, RequestDefinition, HandlerProcess ).
Where: Exchange is a unique exchange name,
ResponseMatchingTag ‒ a local tag for processing the response. For instance, when several identical requests which belong to different users are being sent,
RequestDefinition ‒ request body,
HandlerProcess ‒ handler PID. This process will get a server response.
-
Receiving a response
handle_info( #'$msg'{exchange = EXCHANGE, tag = ResponseMatchingTag,message = ResponsePayload}, State ) -> ...
Where ResponsePayload is server response.
For a server, the process is carried out in two stages too:
- Exchange initialization
- Processing of requests
This pattern can be illustrated by the code. Let’s imagine that we have to create some simple service which provides one method for precise time.
First, let’s put API definition code into api.hrl:
%% ===================================================== %% entities %% ===================================================== -record(time, { unixtime :: non_neg_integer(), datetime :: binary() }). -record(time_error, { code :: non_neg_integer(), error :: term() }). %% ===================================================== %% methods %% ===================================================== -record(time_req, { opts :: term() }). -record(time_resp, { result :: #time{} | #time_error{} }).
Let’s define service controller in time_controller.erl:
%% The example shows the main code only. If you insert it into gen_server pattern, you will get a proper working service. %% gen_server initialization init(Args) -> %% connection to exchange messaging:monitor_exchange(req_resp, ?EXCHANGE, default, self()) {ok, #{}}. %% processing of exchange disconnection events. The same happens if an exchange hasn’t been run yet. handle_info(#exchange_die{exchange = ?EXCHANGE}, State) -> erlang:send(self(), monitor_exchange), {noreply, State}; %% API processing handle_info(#time_req{opts = _Opts}, State) -> messaging:response_once(Client, #time_resp{ result = #time{ unixtime = time_utils:unixtime(now()), datetime = time_utils:iso8601_fmt(now())} }); {noreply, State}; %% gen_server termination terminate(_Reason, _State) -> messaging:demonitor_exchange(req_resp, ?EXCHANGE, default, self()), ok.
The client code is placed in client.erl. To send a request to the service, we can call messaging request API in any part of the client:
case messaging:request(?EXCHANGE, tag, #time_req{opts = #{}}, self()) of ok -> ok; _ -> %% repeat or fail logic end
We don’t know state of the system because its depends on state of various of system components when request arrived. When a request comes, messaging can be not running yet, or service controller may be not ready to process the request. That’s why we have to check messaging response and process a failure.
If a request is delivered, the service can answer with a response or a failure. Let’s process both cases in handle_info/2:
handle_info(#'$msg'{exchange = ?EXCHANGE, tag = tag, message = #time_resp{result = #time{unixtime = Utime}}}, State) -> ?debugVal(Utime), {noreply, State}; handle_info(#'$msg'{exchange = ?EXCHANGE, tag = tag, message = #time_resp{result = #time_error{code = ErrorCode}}}, State) -> ?debugVal({error, ErrorCode}), {noreply, State};
Request-Chunked Response
It’s safer not to send huge messages as they might affect system responsiveness and performance in general. If a response takes up too much memory, splitting is crucial.
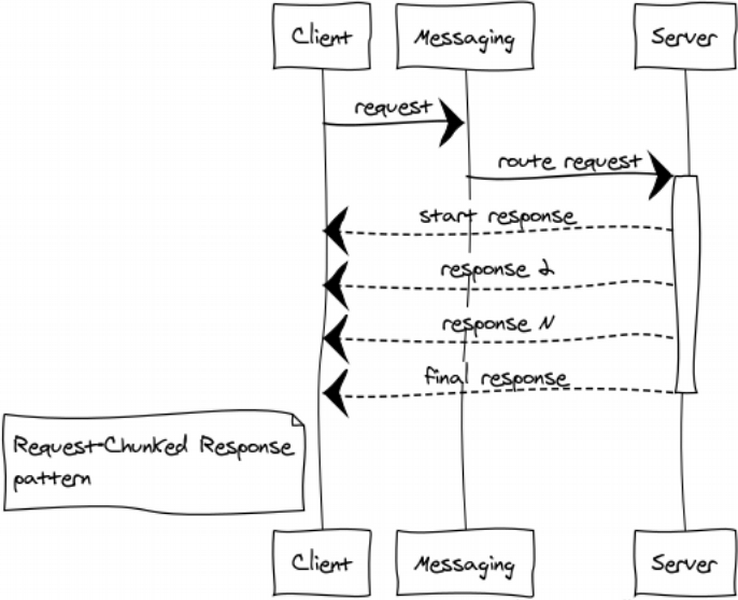
Here is a couple of examples:
- Components are exchanging binary data ‒ some files, for example. Splitting a response into small chunks helps us work with files of any size and prevent memory overflow.
- Listings ‒ for instance, we need to select and transmit all the rows of huge table in database to another component.
Such responses sometimes look like a train. Anyway, 1024 1-MB messages are better than a single 1-GB message.
Erlang cluster constitutes an additional benefit ‒ the load on the exchange and network is reduced as the responses go to the receiver directly, bypassing the exchange.
Response with Request
This one is quite a rare modification of RPC pattern for building dialogue systems.
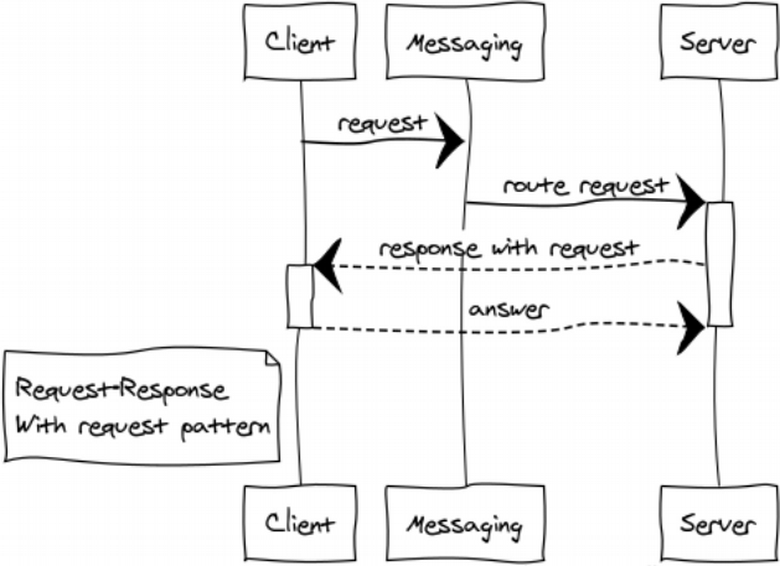
Publish-subscribe (data distribution tree)
Event-driven systems deliver data to users when it is ready. Systems are more inclined to a push-model than to pull or poll ones. This feature enables us not to waste resources while constantly requesting and waiting for data.
The illustration shows the process of message distribution to users subscribed to a certain topic.
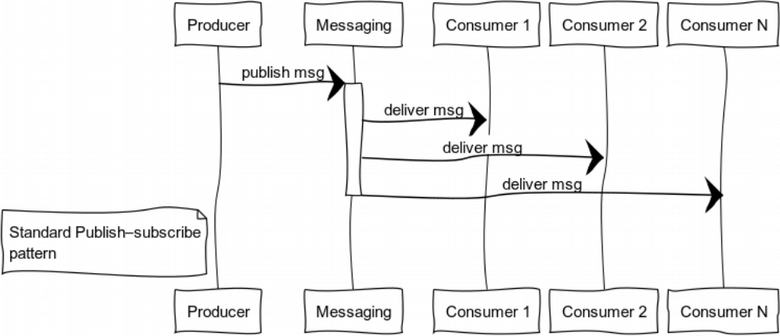
A classic case of this pattern usage is state distribution: it can be game world in computer games, market data on financial exchanges, or useful information in datafeeds.
Take a look at the subscriber code:
init(_Args) -> %% subscribe to exchange, routing key = key messaging:subscribe(?SUBSCRIPTION, key, tag, self()), {ok, #{}}. handle_info(#exchange_die{exchange = ?SUBSCRIPTION}, State) -> %% if an exchange is unavailable, we are trying to reconnect to it messaging:subscribe(?SUBSCRIPTION, key, tag, self()), {noreply, State}; %% process received messages handle_info(#'$msg'{exchange = ?SUBSCRIPTION, message = Msg}, State) -> ?debugVal(Msg), {noreply, State}; %% if a consumer stops, disconnect from exchange terminate(_Reason, _State) -> messaging:unsubscribe(?SUBSCRIPTION, key, tag, self()), ok.
Publisher can publish the message in any suitable place by function call:
messaging:publish_message(Exchange, Key, Message).
where Exchange ‒ exchange name,
Key ‒ routing key,
Message ‒ payload.
Inverted Publish-subscribe
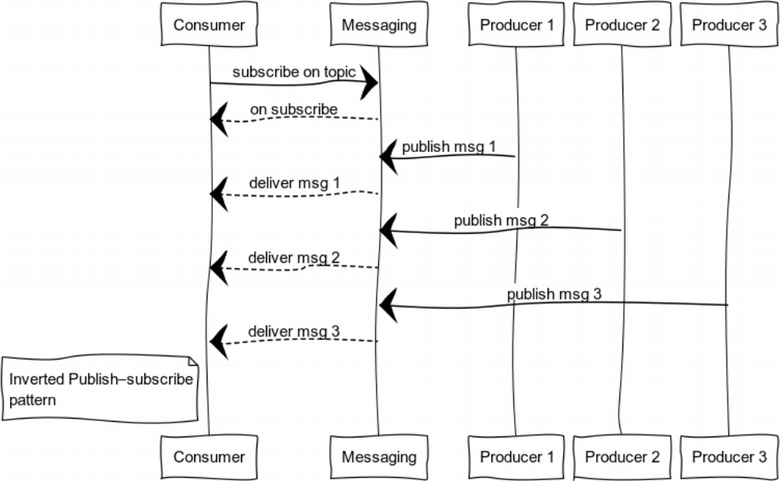
When we invert the pub-sub, we get a pattern which is good for logging. The set of producers and consumers can vary a great deal. The diagram shows a case with one consumer and a number of producers.
Task distribution pattern
Nearly every project challenges us with postponed processing tasks like generating reports, delivery of notifications, getting data from third-party systems. The system capacity is easily scaled by adding workers. All that remains now is to make up a cluster of workers and distribute tasks between them evenly.
Let’s consider an example with 3 workers. At the stage of distributing tasks we are faced with the question of the fairness of this distribution and workers overload. Round-robin will be responsible for providing fairness, while prefetch_limit will prevent workers overload. In transient modes prefetch_limit will not allow one worker to get all the tasks.
Messaging controls queues and processing priority. Workers get tasks as they come. Any task can be completed either successfully or with a failure.
- messaging:ack(Task) ‒ is called when a message is successfully processed
- messaging:nack(Task) ‒ is called in all emergency situations. After having a task back, messaging will resend it to another worker.
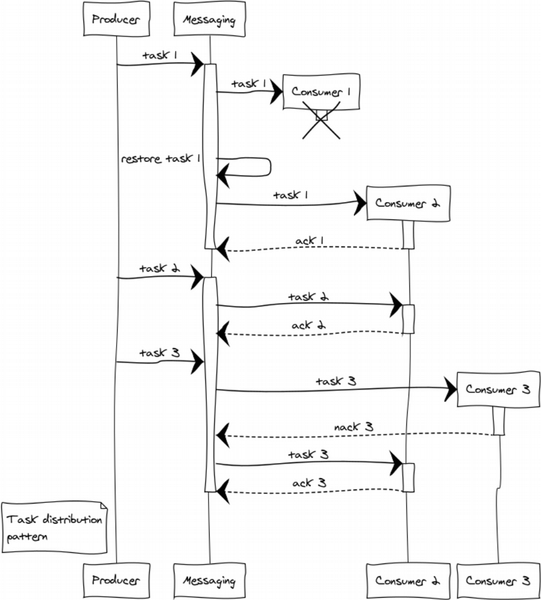
Let’s suppose that a complex failure has happened in processing 3 tasks. Worker 1 crashes after getting the task and fails to inform the exchange. In this case, the exchange redirects the task to another worker on expiry of ack timeout. Worker 3, for some reason, rejects the task and sends nack. As a result, the task goes to another worker which manages to complete it.
Preliminary conclusion
In this article we have taken a closer look at the main building bricks of distributed systems. We have also gained basic understanding of their implementation in Erlang/Elixir.
By combining basic patterns, you can build complex paradigms to deal with emerging challenges.
The final part will focus on some general questions of managing services, routing, and balancing. We will also talk about the practical side of system scalability and fault tolerance.
The end of the second part.