 Vonmo's Blog
Vonmo's Blog
Erlang/Elixir solutions: struggle for quality

Today we are going to talk about logs, quantitative metrics, and how to observe them in order to increase the team reaction rate and reduce the system waiting time in case of an incident.
Erlang/OTP as a framework and ideology of developing distributed systems provides us with regulated approaches to development, proper tools, and implementation of standard components. Let’s assume that we have exploited OTP’s potential and have gone all the way from prototype to production. Our Erlang project feels perfectly fine on production servers. The code base is constantly developing, new requirements are emerging alongside with functionality, new people are joining the team. Everything is, like…fine? However, from time to time something might go wrong and any technical issues combined with human factor lead to crash.
As you just can’t have all the bases covered and foresee all the potential dangers of failures and problems, then you have to reduce the system waiting time via proper management and software solutions.
In any information system there is a risk of failures of a different nature, such as:
- hardware and power failures
- network failures: configuration mistakes and broken or out of date firmware
- logical mistakes: from algorithm coding problems to architecture-related issues which appear at the border of subsystems and systems
- safety issues alongside with cyber attacks and hacks, including internal falsification
First, let’s delineate the responsibilities. Infrastructure monitoring will deal with networking software and data transmission networks. Such monitoring might be organized with the help of zabbix. Much has been written about its setup, and we are not going to repeat it.
From developer’s point of view, the problem of access and quality is closely connected to early detection of errors and performance issues, as well as quick response to them. To do so, you need certain approaches and assessment tools. Well, let’s try to figure out quantitative metrics. By analyzing them on different stages of project development and operation, we can significantly improve its quality.
Build systems
Let us begin with recalling, once again, how vital engineering approach is in testing and developing software. Erlang/OTP offers not one, but two testing frameworks: eunit and common test.
We can use the number of successful or problematic tests, their run-time and test coverage as metrics for primary assessment of the code base and its dynamics. Both frameworks enable us to save test results in Junit. For instance, with rebar3 and ct you need to add the following into rebar.config:
{cover_enabled, true}. {cover_export_enabled, true}. {ct_opts,[ {ct_hooks, [{cth_surefire, [{path, “report.xml”}]}]} ]}.
The number of successful and failed tests makes it possible to build a trend chart.
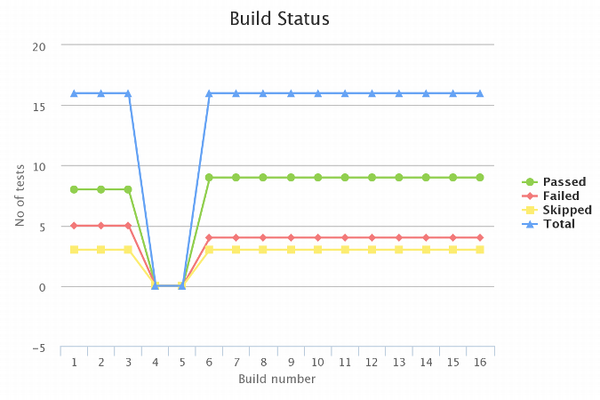
By looking at it, you can assess team’s performance and tests regression. For example, you can get a graph like this in Jenkins, using Test Results Analyzer Plugin. Usage of metrics allows you to notice and prevent breaking or slowing down the project tests and fix problems before releasing.
Application metrics
Apart from OS metrics, application metrics should also be included into monitoring. It might be page views per second, number of payments, and other crucial indicators.
In my own projects I use the code template ${application}.${metrics_type}.${name} for naming the metrics. This naming helps to get metric lists like
messaging.systime_subs.messages.delivered = 1654 messaging.systime_subs.messages.proxied = 0 messaging.systime_subs.messages.published = 1655 messaging.systime_subs.messages.skipped = 3
The more metrics we have, the easier it is to get an idea of what’s going on within a complicated system.
Erlang VM metrics
Special attention should be given to Erlang VM monitoring. ‘Let it crash’ ideology is truly wonderful, and proper usage of OTP will definitely help you out in restoring applications and processes. But don’t forget about Erlang VM itself: although it’s difficult to crash it, but still possible. All potential cases are based on running out of resources. Let’s list the most popular ones:
Atom table overflow
Atoms perform as identificators whose main aim is to improve code readability. Once created, they stay in Erlang VM memory forever because they are not cleaned away by the garbage collector. Why is that? Well, the garbage collector is working within each process just with this process data. Atoms, in their turn, might be distributed across data structures of a number of processes. 1,048,576 atoms can be created by default. In the articles on killing Erlang VM you will probably come across something like that:
[list_to_atom(integer_to_list(I)) || I <- lists:seq(erlang:system_info(atom_count), erlang:system_info(atom_limit))].
as an illustration of the above-mentioned effect. This problem looks quite artificial and unlikely to happen in real systems. There have been cases, though… For instance, in an an external API handler in queries analysis binary_to_atom/2 is used instead of binary_to_existing_atom/2, or list_to_atom/1 instead of list_to_existing_atom/1.
To monitor atoms state, the following parameters are good to use:
- erlang:memory(atom_used) — memory used by atoms
- erlang:system_info(atom_count) — number of atoms created in a system.
Together with erlang:system_info(atom_limit) it’s possible to calculate atoms utilization.
Processes leaking-out
It’s worth mentioning that with reaching process_limit (+P argument erl) erlang vm does not crash but falls into disrepair — even connecting to it seems impossible in such case. Eventually, running out of memory due to its allocation to leaking processes will result in erlang vm crash.
To monitor process state, let’s use the following parameters:
- erlang:system_info(process_count) — the number of processes currently existing at the local node. Together with erlang:system_info(process_limit), you can calculate the processes usage.
- erlang:memory(processes) — the total amount of memory currently allocated for the Erlang processes.
- erlang:memory(processes_used) — the total amount of memory currently used by the Erlang processes.
Mailbox overflow
When a producer process is sending messages to a consumer process without confirmation pending is a great illustration of that. Meanwhile, receive in a consumer process is ignoring the messages because of a missing or wrong pattern. As a result, all the messages are being stored in the mailbox. Erlang has a mechanism of slowing down the sender if the processor can’t cope with the processing. However, vm crashes after available memory exhaustion anyway.
You can understand if you have any mailbox overflow issues with the help of etop.
$ erl -name etop@host -hidden -s etop \
-s erlang halt -output text -node dest@host \
-setcookie some_cookie -tracing off \
-sort msg_q -interval 1 -lines 25
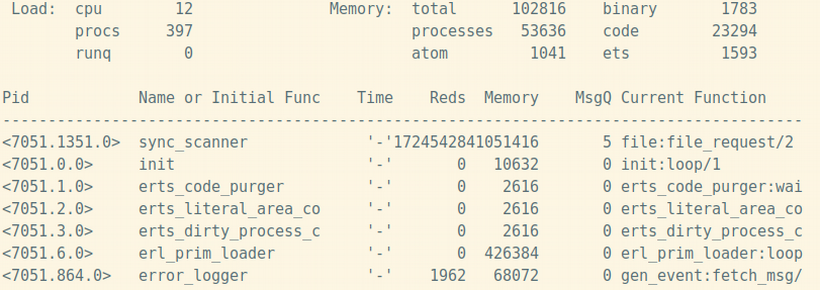
The number of problematic processes can be taken as metrics for constant monitoring. To identify those processes, the following function may be used:
top_msq_q()-> [ {P, RN, L, IC, ST} || P <- processes(), { _, L } <- [ process_info(P, message_queue_len) ], L >= 1000, [{_, RN}, {_, IC}, {_, ST}] <- [ process_info(P, [registered_name, initial_call, current_stacktrace]) ]].
This list can also be logged. In this case, the analysis of the problem is simplified after getting a notification from monitoring.
Binary overflow
Memory for huge (more than 64 bytes) binaries is allocated on the heap. Allocated memory unit has a reference counter which shows the number of processes having access to it. After you reset the counter, clean up is performed. As easy, as that, right. However, there are some tiny little issues. For instance, there is a chance of appearing a process that will generate so much garbage that the system won’t have enough memory for clean-up.
erlang:memory(binary) performs as metrics for monitoring. It shows the memory allocated for binaries.
All in all, we have mentioned all the cases which lead to vm crash. However, it seems rational to keep monitoring other equally important parameters which may directly or indirectly affect your apps proper functioning:
- ETS tables memory: erlang:memory(ets).
- Memory for compiled modules: erlang:memory(code). If your solutions don’t use dynamic code compilation, this parameter can be excluded. There should be a specific reference to erlydtl. If you compile templates dynamically, beam is created and gets loaded into vm memory. It can also lead to memory leaks.
- System memory: erlang:memory(system). Shows the memory used by runtime erlang.
- Total memory utilization: erlang:memory(total). The total amount of memory currently allocated for the Erlang processes.
- Information on reductions: erlang:statistics(reductions)
- The count of all processes which are ready for execution: erlang:statistics(run_queue)
- Vm uptime: erlang:statistics(runtime) — enables you to understand without analysing the logs if there was a restart
- Network activity: erlang:statistics(io)
Sending metrics to zabbix
Let’s create a file which contains app metrics and erlang vm metrics. We will update it once in N seconds. For each erlang node the metrics file must include all the apps metrics and erlang vm metrics. Eventually, we should have something like this:
messaging.systime_subs.messages.delivered = 1654
messaging.systime_subs.messages.proxied = 0
messaging.systime_subs.messages.published = 1655
messaging.systime_subs.messages.skipped = 3
…
erlang.io.input = 2205723664
erlang.io.output = 1665529234
erlang.memory.binary = 1911136
erlang.memory.ets = 1642416
erlang.memory.processes = 23596432
erlang.memory.processes_used = 23598864
erlang.memory.system = 50883752
erlang.memory.total = 74446048
erlang.processes.count = 402
erlang.processes.run_queue = 0
erlang.reductions = 148412771
…
With the help of zabbix_sender we’ll be sending this file to zabbix where the graphic representation will be available, alongside with the possibility to create automatization and notification triggers.
Now, as in our monitoring system there are metrics together with automatization and notification triggers, we have a chance to avoid failures and breakdowns. That’s because we are able to react to all dangerous deviations from fully functional mode in advance.
Central log collection
If there is just a couple of servers in a project, it’s possible to do without centralized log collecting. When a distributed system with a lot of servers, clusters and environments appears, however, it’s necessary to deal with log collecting and viewing.
To perform logging in my projects, I use lager. On the way from prototype to production, projects go through the following stages of log collecting:
- The simplest logging with downloading logs to a local file or even stdout (lager_file_backend)
- Central log collecting with using, for instance, syslogd and sending all the logs to collector automatically. For such a scheme, lager_syslog is optimal. The main disadvantage, though, is that you have to get to the log collector server, find the file with the logs required, and somehow filter the events searching for the ones you need for debugging.
- Central log collecting with saving into repository with filter and search opportunities.
Now, it’s time to talk about benefits, drawbacks, and quantitative metrics which you can apply using the later type of log collecting. We’ll do it by example of certain implementation — lager_clickhouse, which I use in most of my projects. There is a couple of things to say about lager_clickhouse. This is a lager backend for saving events to clickhouse. It’s an internal project so far, but there are plans to make it open. During lager_clickhouse developing, it was necessary to bypass some certain clickhouse features. For example, buffering of events was used in order not to query to clickhouse too often. The effort was paid off with steady work and good performance.
The main disadvantage of this approach with saving to repository is creating an additional entity — clickhouse. In such case, you have to write the code for saving events into it, as well as user interface for searching and analysing events. Also, for some projects using tcp for sending logs might be critical.
The advantages, as it seems to me, overweight all the possible drawbacks:
-
Quick and easy search for events:
- Filtering by date without having to search a file/files on the central server which contains the variety of events.
- Filtering by environment. Logs from various subsystems and often from different clusters are written into the same storage. Currently, there is a division by tags. Every node can be marked by a tag or set of tags which are defined in config file of the node.
- Filtering by node name.
- Filtering by the name of the module which sent the message.
- Filtering by event type
- Text search
The screenshot below demonstrates an example of log viewer interface:
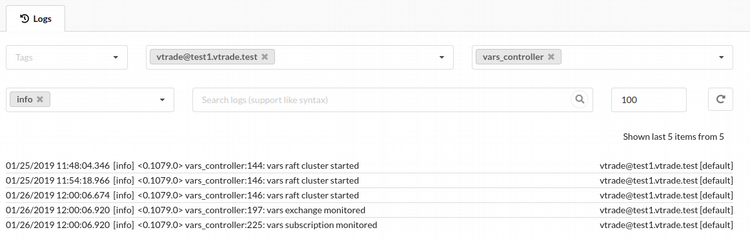
-
A possibility to fully automate the process. With implementing a log storage, it’s possible to get real-time data about the number of mistakes, critical issues, and system performance. Analysing this data in real time and imposing some limits, we can generate warnings for nonfunctional state of the system and handle it in automatic mode: execute scripts to manage the issue and send notifications:
- in case of a critical error
- in case of an outbreak of errors
- A certain metric is the event generation speed, as many new events appear in a log. You can almost always know an estimate of logs generated by project per unit of time. If it is exceeded, something is definitely going wrong.
The further development of the topic of emergencies automation is the implementation of lua scripts. Any developer or administrator can write a script for processing logs and metrics. Scripts result in flexibility and enable you to create personal scenarios of automation and notification.
Results
Metrics and logs, alongside with proper tools to analyse them, are crucial for understanding processes within a system and investigating incidents. The more information about the system we have, the easier it is to analyse its behaviour and fix problems at an early stage. If our measures haven’t worked well, we always have graphs and detailed logs at our disposal.
How do you exploit Erlang/Elixir solutions? Ever met any interesting cases in production?