 Vonmo's Blog
Vonmo's Blog
Erlang. Safe optimization with NIF on Rust
The article deals with Erlang and Rust integration with reference to Burton Bloom’s probabilistic data structure implementation. The later is used to test with the precision required whether an element belongs to a set.
Language choice
Performance tests based on computing tasks clearly demonstrate what languages Erlang teams up with.

As it cannot boast super-fast arithmetic, any attempt to use it for solving complicated computing tasks looks quite weird. However, it’s just perfect for the issues arising while developing and exploiting multi-tenant systems. The language has an excellent scheduler and a garbage collector, alongside with speedy network and binary data processing. No wonder that it does its utmost in competitive distributed environment. So, if you ask me, Erlang is a kind of system glue in distributed server-side apps architecture.
In real-time systems there might occur local computing tasks which hinder the system and worsen general UX. It’s not a rare case when just 1% of hindering code adversely impacts the other 99% of the system. To solve this problem, Erlang, starting from R13B03, is equipped with the Native Implemented Functions (NIFs) mechanism.
Among numerous myths about Erlang there is a paragraph 2.7. It’s there where developers warn you that NIF interface usage should be of last resort. This is due to the fact that NIF doesn’t always guarantee speed enhancement, and its potential implementation faults might be related to VM crashes.
Official examples of NIF implementation are available for C. Both C and C++ code is easy to be made unsafe. For instance, one might face with memory overflowing or even miss the operation of releasing of resources allocated. I believe that the problem is aggravated by the context switch factor. When a programmer, mainly working with Erlang, switches to low-level C, the likelihood of the above-mentioned issues grows, especially within deadlines.
So, it would be ideal to get a solution as fast as in C/C++, but at the same time safe and easy to support. Let’s have a look at the most productive languages in terms of computing.
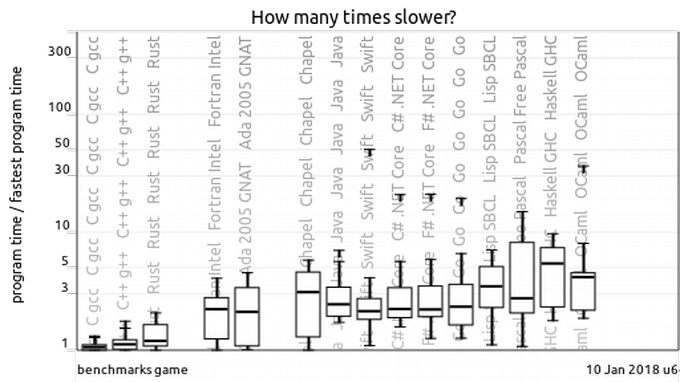
From the language requirements point of view the following is worth mentioning:
- Safety. Under no circumstances should a solution break Erlang VM.
- Performance. It should be compared to C++ in terms of efficiency.
- Possibility of using in NIF mode.
- Development speed. There should be a good standard library and a wide choice of third-party libraries which will ensure comfortable language ecosystem.
From all productive languages the one which seems to be the most suitable is definitely Rust. It offers high efficiency and a fault-tolerant development model, as well as active community. One more obvious benefit is data immutability and transparent multi-threading model.
It should be noted that there is another optimisation option. If we can neglect time and costs of an extra call via EPMD, then we can, as well, choose Erlang Node instead of NIF. To address the challenge, Java, Go, Rust or Ocaml (based on personal experience) might be used. Erlang Node can be run on the same machine or even on the other side of the world.
Implementation
An overview of existing solutions in Rust
After a quick search, a number of libraries for writing NIF in Rust might be found. Let’s take a look at some.
- Rustler. Perhaps, the most popular and functional library. However, the authors mainly focus on Elixir support. In issue they suggest to drag mix into any Erlang project. What’s more, there is no documentation on how to use it within Erlang.
- erlang-rust-nif is a low-level implementation of NIF and approach to extension development. The code looks like basic translation from C. The assembly is not universal and has boundary conditions.
- erlang_nif-sys. Low-level functional bundle which operates as a basis for Rustler and takes much time and effort to write NIF.
- bitwise_rust. This one demonstrates how to work with a scheduler. It also is a wrapper over ANSI C API without syntax sugar.
Since development speed is one of the requirements, Rustler looks most attractive. However, it would be better not to add any extra dependency like Elixir or mix collector into the project.
Rustler
All in all, it was decided to opt for Rustler but with no additional dependencies. Such a decision answers the question ‘Why on Earth should we drag Elixir into Erlang project?’ and also follows the KISS principle. Rebar3 is taken as a build system. The fastest and easiest step is pre_hooks identification for our Rust code compilation. To that end, let’s write in hook test profile:
{pre_hooks, [ {"(linux|darwin|solaris|freebsd)", compile, "sh -c \"cd crates/bloom && cargo build && cp target/debug/libbloom.so ../../priv/\""} ]}
Then, let’s add an option release in production environment and the following to the production profile:
{pre_hooks, [ {"(linux|darwin|solaris|freebsd)", compile, "sh -c \"cd crates/bloom && cargo build --release && cp target/release/libbloom.so ../../priv/\""} ]}
After all these manipulations we’ve got a dynamic library priv/libbloom.so which is fully ready to be loaded into Erlang VM. You might find all the details and an example of using Rustler in an Erlang project in the project repository.
Bloom’s filter
As Rust ecosystem offers ready-made implementations of Bloom’s filter, all we need to do is to pick up a suitable one and to add it into cargo.toml. In current project bloomfilter = “0.0.12” is being used. It implements the following functions:
- new(bitmap_size, items_count) — filter initialization. bitmap_size и items_count — calculated values, there is a number of ready-made calculators.
- serialize() — filter packaging. For instance, you can use it for further storage on hard drive or network data transmission.
- deserialize() — loads the filter state.
- set(key) — adds an element to array.
- check(key) — checks the element belonging to array.
- clear() — clears the filter.
Erlang
It’s worth mentioning that extension loading into Erlang is an absolutely transparent process. After you load your module, the call on_load is performed. Here you should implement NIF loading via erlang:load_nif/2. In doing so, calls processing will be performed transparently in Rust as well. It’s just common decency to generate erlang:nif_error/1 in case if NIF has not been loaded.
You can find the detailed description of the project environment in the following article.
Results
As a result of the work completed, we’ve got an efficient ans safe extension. In our projects this one can reduce the volume of requests to data repository by up to 10 times. What’s more, it is able to serve more than 500k RPS client requests per machine. The extension source code is available on github.