 Vonmo's Blog
Vonmo's Blog
Vonmo Trade Experiment. Part 4: Stock charts

In the previous articles we dealt with order creating and processing. Today’s one will focus on processing and storage of the information which is essential for graphic instruments of market analysis – or just stock charts.
To assess the market condition properly, we can’t manage with just an order book and trade history. We need an instrument which will help to see the market price trend clearly and fast. Charts can be divided into two types:
- Line charts
- Interval graphs
Line charts
These are the easiest and the do not require any preparation to be understood. Line charts show the dependence of a financial instrument price on time.
Chart resolution
If we start building a chart based on all the price changes, i.e. every closed deal gets to the chart, it will be really difficult to take. Also, the capacities used for this chart processing and delivery will be wasted. That’s why data should be decimated: the timeline is split into intervals, and the prices within these intervals are aggregated. Resolution is the size of a basic interval of timeline splitting: second, minute, hour, day etc.
Bar chart
They belong to interval graphs. To increase informativeness, we need to show the price information at the beginning and at the end of the interval for every single interval. We also need to show the maximum and the minimum price. The graphic representation of this set is called a bar. Let’s look at a bar scheme:
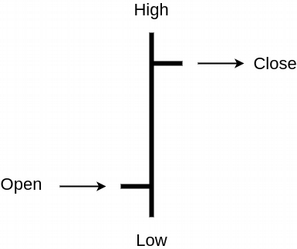
A sequence of bars makes a bar chart:
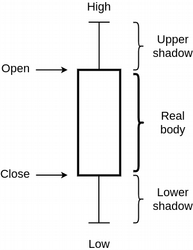
Candlestick chart
Like bar charts, they belong to interval graphs. They are the most popular type of graph in technical analysis. A ‘candlestick’ consists of black or white body and shadows – higher one and lower one. Sometimes a shadow is called a wick. The highest and the lowest borders of a candlestick illustrate the highest and the lowest price during the time interval represented. The body borders show the opening price and the closing price. Let’s draw a candlestick:
A sequence of candlesticks make a candlestick chart:
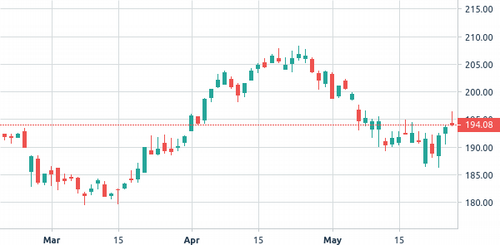
OHLCV notation
In the previous article we dealt with the scheme of data storage for a graph in postgresql and built a table for data source which will store aggregated data:
CREATE TABLE df ( t timestamp without time zone NOT NULL, r df_resolution NOT NULL DEFAULT '1m'::df_resolution, o numeric(64,32), h numeric(64,32), l numeric(64,32), c numeric(64,32), v numeric(64,32), CONSTRAINT df_pk PRIMARY KEY (t, r) )
These fields don’t need to be explained except, probably, the r field which is the row resolution. In postgresql there are enumerations which are great to use when we know the value set for a field in advance. Let’s define a new type for permissible chart resolutions via listings. Let it be a row from 1 minute to 1 month:
CREATE TYPE df_resolution AS ENUM ('1m', '3m', '5m', '15m', '30m', '45m', '1h', '2h', '4h', '6h', '8h', '12h', '1d', '3d', '1w', '1M');
It’s important to find a balance between IO performance, CPU performance, and final cost of ownership. At the moment, there are 16 resolutions defined in the system. Two obvious solutions present themselves:
- We can calculate and store all resolutions in the base. This option is convenient because, while selecting, we don’t spend capacity on interval aggregating and all data are ready for output straightaway. There will be slightly more than 72k records for one instrument per month. Looks easy and convenient, doesn’t it? However, such table will change too often because for each price update we need to create or update 16 records in the table and rebuild the index. There might be an issue in postgresql with garbage collecting too.
- Another option is to store a single basic resolution. While selecting from basic resolution, it’s necessary to build the resolutions required. For example, if we store a minute resolution as the basic one, 43k records will be created for each instrument per month. This way, compared to the previous option, we are reducing the record volume and overhead costs by 40%. However, CPU load is increasing at the same time.
As mentioned before, it’s really vital to strike a balance. That’s why a middle ground would be to store not just one basic resolutions, but several: 1 minute, 1 hour, 1 day. Under this scheme, there are 44,6k records created for each instrument per month. Optimization of record volume will be 36% and CPU load will be acceptable as well. For instance, to build week intervals we’ll need to read from the disc and aggregate the data of 7 day resolutions instead of reading and aggregating 10080 records with minute basic resolution.
OHLCV storage
OHLCV is a time series in its nature. As is known, relational database is not suitable for such data storage and processing. Our project deals with this problem with the help of Timescale. Timescale improves the performance of insert and update operations, and enables to configure partitioning, and provides the analytical functions which are specially optimized for working with time series.
To create and update the bars, we’ll need standard functions only:
date_trunc(‘minute’ | ’hour’ | ’day’, transaction_ts) – to find the beginning of the interval of a minute, hour, and day resolution respectively.greatestиleast– to define the maximum and minimum price.
Thanks to upsert api, only one update request is performed per each transaction.
What I got in the end is the following SQL for fixing market changes in basic resolutions:
FOR i IN 1 .. array_upper(storage_resolutions, 1) LOOP resolution = storage_resolutions[i]; IF resolution = '1m' THEN SELECT DATE_TRUNC('minute', ts) INTO bar_start; ELSIF resolution = '1h' THEN SELECT DATE_TRUNC('hour', ts) INTO bar_start; ELSIF resolution = '1d' THEN SELECT DATE_TRUNC('day', ts) INTO bar_start; END IF; EXECUTE format( 'INSERT INTO %I (t,r,o,h,l,c,v) VALUES (%L,%L,%L::numeric,%L::numeric,%L::numeric,%L::numeric,%L::numeric) ON CONFLICT (t,r) DO UPDATE SET h = GREATEST(%I.h, %L::numeric), l = LEAST(%I.l, %L::numeric), c = %L::numeric, v = %I.v + %L::numeric;', df_table, bar_start, resolution, price, price, price, price, volume, df_table, price, df_table, price, price, df_table, volume ); END LOOP;
While selecting, the following functions will serve us for aggregating the intervals:
time_bucket– to split into intervalsfirst– to find the opening price –Omax– the maximum price per interval –Hmin– the minimum price per interval –Llast– to find the closing price –Csum– to find the trade volume –V
The only problem with Timescale is the limitation of time_bucket function. It enables to manipulate the intervals less than a month only. To build a month resolution, we should use the standard function date_trunc.
API
To display the graphs on the client, we’ll use lightweight-charts from Tradingview. This library enables to configure the appearance of the charts and is quite convenient to exploit. I’ve got the following charts:
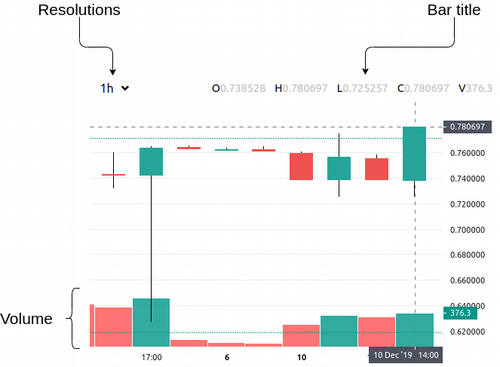
As the main part of the browser-platform interaction is carried out via websocket, there are no problems with interactivity.
Data source
The data source for charts (or data feed) must return the required part of the time series in needed resolution. To save the traffic and processing time on the client, the server must pack the points.
API for data feed should be designed so that you can request multiple graphs in a single request and subscribe to their updates. This will reduce the number of commands and responses in a channel. Let’s consider a request of the last 50 minutes for USDGBP with automatic subscription to the graph updates:
{ "m":"market", "c":"get_chart", "v":{ "charts":[ { "ticker":"USDGBP", "resolution":"1h", "from":0, "cnt":50, "send_updates":true } ] } }
For sure, we can request the date range (from, to), but as we know each bar interval, declarative API indicating the moment and the number of bars seems more convenient to me. Data feed will respond to this request in the following way:
{ "m":"market", "c":"chart", "v":{ "bar_fields":[ "t","uts","o","h","l","c","v" ], "items":[ { "ticker":"USDGBP", "resolution":"1h", "bars":[ [ "2019-12-13 13:00:00",1576242000,"0.75236800", "0.76926400","0.75236800","0.76926400","138.10000000" ], .... ] } ] } }
bar_fields field contains the information about the position of the elements. Further optimization involves putting this field into the client configuration which it gets from the server during the client initialization. This way, the client gets a necessary part of historical data and builds the initial state of the graph. If the state changes, the clients gets an update on the last bar only.
{ "m":"market", "c":"chart_tick", "v":{ "ticker":"USDGBP", "resolution":"1h", "items":{ "v":"140.600", "ut":1576242000, "t":"2019-12-13T13:00:00", "o":"0.752368", "l":"0.752368", "h":"0.770531", "c":"0.770531" } } }
Interim conclusion
Over the whole series of articles we went through the theory and practice of building an exchange. Now it’s time to put the system together. The following article will tell about the development of user graphic interfaces: service UI to operate the platform and UI for end users. Also, you’ll be able to take a look at the demo version of Vonmo Trade.
Thanks to Nadezda Popova for proofreading.