 Блог Vonmo
Блог Vonmo
Эксперимент VonmoTrade. Часть 3: Книга ордеров. Обработка и хранение торговой информации
В прошлой статье цикла мы познакомились с типами биржевых заявок. Сегодня мы разберем книгу ордеров, обработку заявок и вопросы связанные с организацией хранения торговой информации.
Спрос и предложение
Наверняка вы помните закон спроса и предложения из курса экономики, который показывает механику рынка по формированию цен:
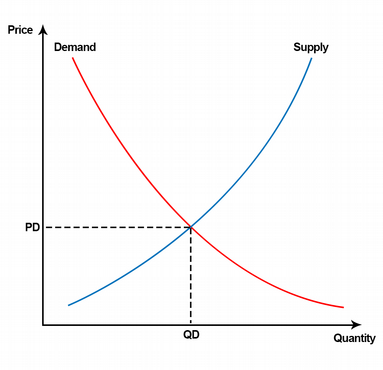
Эта же механика работает и на биржах.
Книга ордеров — список, в который заносят лимитные заявки продавцов и покупателей, таким образом показывая текущий интерес к определенному финансовому инструменту.
Если прошлый график преобразовать применительно к книге ордеров, то получится что-то подобное:
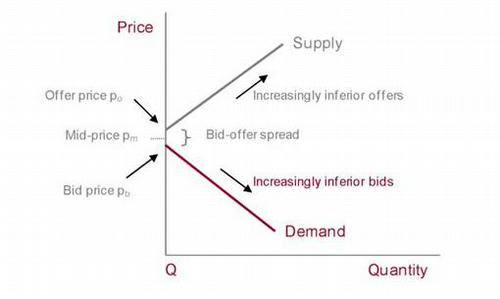
Здесь мы видим, что рыночная цена получается при равенстве максимальной цены спроса и минимальной цены предложения. Спрэд — разница этих цен. Это важный индикатор, так как он связан с ликвидностью инструмента. Чем меньше спрэд, тем более ликвиден инструмент. Для обеспечения ликвидности в рамках биржевого торга, часто вводят ограничение на максимальный спрэд, при превышении которого торги могут быть остановлены.
Создание заявок
Рассмотрим жизненный путь заявки от поступления на биржу до выполнения или отмены. Для простоты будем рассматривать случай валютного рынка. За логику обработки заявок отвечает специальный процесс, назовем его контроллером рынка.
Итак, участник создает заявку, она попадает на биржу. Контроллер обязан убедиться, что у участника достаточно ликвидности для создания запрашиваемого типа ордера. Источником информации может служить внутренний сервис аккаунтинга, либо же любые внешние API.
Для немедленного исполнения этой заявки, на рынке должна существовать встречная, так называемая парная заявка. В случае если встречная заявка есть, из найденной пары меньший ордер выполняется полностью, а больший частично. Конечно, если частичное выполнение разрешено торговыми инструкциями заявки. В случае отсутствия встречной заявки, новый ордер попадает в книгу ордеров и занимает свое место в списке ордеров своего типа. Поскольку в книгу ордеров попадают только отложенные ордеры, для ордеров других типов необходимо выделить свои списки.
Во всех списках заявок сторона покупки должна быть отсортирована по убыванию, а сторона продажи по возрастанию цены. Первый элемент списка лимитных ордеров для каждой стороны формирует лучшую цену спроса и предложения соответственно.
Еще одним важным моментом является очередность выполнения. Контроллер должен реализовывать FIFO. Поэтому, если цены двух заявок совпадают, выше должна оказаться созданная раньше.
В интерфейсе пользователя книга выглядит как таблица состоящая из набора уровней цен, в которой представлены лимитные заявки как на покупку, так и на продажу.
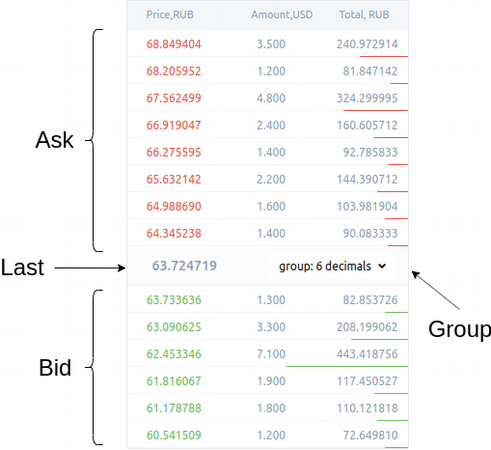
Для дополнительного визуального разграничения, заявки на продажу и покупку имеют разные цвета.
Агрегирование уровней
Глубина книги — количество уровней цен. Для активных рынков с большим числом отложенных заявок, отстоящих друг от друга на минимальное расстояние, глубина может быть очень большой для отображения в терминале трэйдера. Чтобы оценить всю книгу, нужен инструмент группировки уровней. Отсекая по одному знаку после запятой и группируя уровни, мы можем с каждым шагом сокращать их количество.
Выполнение и отмена заявок
После того как ордер, находящийся в книге, выполняется или отменяется, контроллер должен обновить книгу, удалив этот ордер и уведомив всех заинтересованных об изменениях в книге.
Архитектура и масштабирование обработчиков
С учетом требуемой производительности и надежности, необходимо определить подходы к масштабированию приложения и системы хранения данных.
Обычно для бирж используют вертикальное масштабирование. Код обработки заявок и аккаунтов пользователей исполняется на одной машине в рамках единого монолита. Подобный подход показывает хорошую производительность, но имеет существенное ограничение — в любом случае вертикальное масштабирование имеет предел, как по процессорной мощности, так и по объему хранилища.
В рамках эксперимента, я решил, что обработка рынков должна масштабироваться горизонтально. Каждый отдельный инструмент обрабатывается своим процессом. Процессы распределяются между узлами кластера автоматически. В случае отказа, рынок переносится на другой узел без потери состояния.
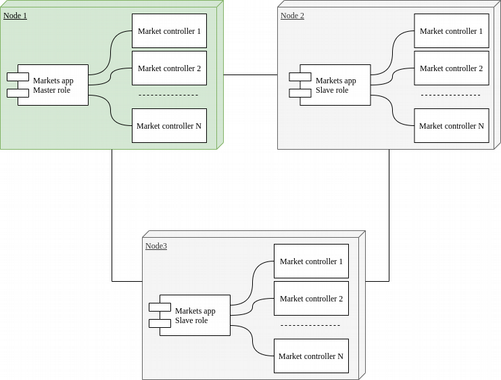
Формула системы крайне проста: М обработчиков распределены на K узлах кластера и используют L хранилищ данных. Подобная схема позволяет масштабировать систему примерно до 150 узлов. А каждый контроллер рынка может обработать около 30к RPS.
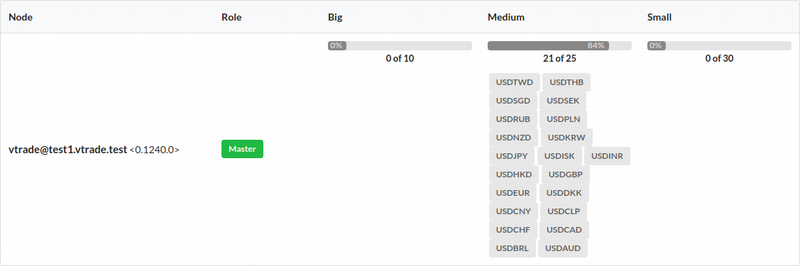
Так как поток заявок на всех рынках разный и зависит от активности пользователей, рынки можно разделить на несколько групп: маленькие, средние и большие. Каждый узел имеет настройки позволяющие указать лимиты по количеству рынков, которые он может обработать. Мастер автоматически и равномерно распределяет рынки одного типа по узлам кластера. В случае изменения состава кластера, рынки перераспределяются. Таким образом достигается более или менее равномерное распределение нагрузки на систему. Примерный вид узлов в интерфейсе управления биржей:
Хранение данных
Книга ордеров постоянно изменяется и должна находиться в памяти. Для MVP в качестве in-memory хранилища я выбрал Tarantool с WAL. Все исторические данные будут записываться в PostgreSQL.
Схема хранения текущих и исторических данных должна соответствовать выбранной схеме масштабированию кода обработчиков. Каждый рынок может использовать свой postgres и tarantool. Для этого объединим пару postgresql и tarantool в единую сущность — хранилище рыночных данных.
При настройке рынка администратор имеет возможность управлять хранилищами. Чтобы сохранить гибкость, вместо реквизитов доступа к конкретным инстансам postgresql и tarantool, будем указывать уникальный идентификатор пула подключений. Интерфейс этих пулов поддерживает платформа. Таким образом, хранилище в интерфейсе администратора выглядит следующим образом:

При настройке рынка администратор должен указать как минимум одно хранилище для каждого рынка. Если указать несколько, получится рынок с логической репликацией данных. Эта функция позволяет конфигурировать надежность и производительность схемы хранения данных.
Данные книги ордеров
Tarantool для организации хранимых данных использует спейсы. Декларация необходимых спейсов для книги ордеров выглядит следующим образом:
book = { state = { name = 'book_state', id = 1, }, orders = { limit = { buy_orders = { name = 'limit_buy_orders', id = 10, }, sell_orders = { name = 'limit_sell_orders', id = 20, }, }, market = { buy_orders = { name = 'market_buy_orders', id = 30, }, sell_orders = { name = 'market_sell_orders', id = 40, }, }, ... }, orders_mapping = { name = 'orders_mapping', id = 50, }, }
Поскольку на одном инстансе tarantool свои данные могут хранить несколько рынков, во все сущности добавим идентификатор рынка. Текущая реализация книги построена по принципу один раз считаем, много раз отдаем. При операциях обновления книги, происходит автоматический пересчет группировок. Например, мы добавляем ордер на рынок, точность для цен 6, возможны 6 группировок цен + один срез с исходными данными ордера, которые необходимо обновить.
Для выдачи списков активных ордеров клиента существует куча ордеров orders_mapping.
Благодаря модели данных tarantool, с помощью комбинации индексов и различных итераторов выборки, lua-код реализующий хранилище книги ордеров занимает всего 600 строк (вместе с инициализацией).
Исторические данные
Данные рынков хранятся в отдельных таблицах для каждого рынка. Рассмотрим набор базовых таблиц.
История выполненных заявок
Для сохранения результатов обработки заявок служит таблица history. В нее попадают полностью выполненные заявки, а также отмененные, но частично выполненные.
CREATE TABLE public.history ( id uuid NOT NULL, ts timestamp without time zone NOT NULL DEFAULT now(), owner character varying(75) COLLATE pg_catalog."default" NOT NULL, order_type integer NOT NULL, order_side integer NOT NULL, price numeric(64,32) NOT NULL, qty numeric(64,32) NOT NULL, commission numeric(64,32) NOT NULL, opts jsonb NOT NULL, CONSTRAINT history_pkey PRIMARY KEY (id, ts) )
На ее основе строится выдача для конечных пользователей по истории их торгов.
Исторический датафид
Для целей анализа, а также формирования исторического датафида, после каждой транзакции контроллер рынка должен сохранить информацию об этом событии. Для фиксации событий изменений рынка служит таблица ticks:
CREATE TABLE public.ticks ( ts timestamp without time zone NOT NULL, bid numeric(64,32) NOT NULL, ask numeric(64,32) NOT NULL, last numeric(64,32) NOT NULL, bid_vol numeric(64,32), ask_vol numeric(64,32), last_vol numeric(64,32), opts jsonb DEFAULT '{}'::jsonb, CONSTRAINT ticks_pk PRIMARY KEY (ts) )
В ней хранятся цены и объемы рынка после совершения транзакции, а поле opts содержит служебную информацию, например описание заявок участвующих в транзакции.
Датафид для графиков
Для построения торговых графиков вполне достаточно таблицы ticks. В ней содержится так называемый сырой поток, но postgresql имеет мощные аналитические функции и позволяет агрегировать данные по запросу. Проблемы начинаются, когда данных слишком много и мощности уже не хватает. Для решения создадим таблицу с предварительно рассчитанными данными:
CREATE TABLE public.df ( t timestamp without time zone NOT NULL, r df_resolution NOT NULL DEFAULT '1m'::df_resolution, o numeric(64,32), h numeric(64,32), l numeric(64,32), c numeric(64,32), v numeric(64,32), CONSTRAINT df_pk PRIMARY KEY (t, r) )
Итог
Мы разобрались в основных моментах организации книги ордеров и механизма обработки заявок, а также немного погрузились в практику работы с рыночными данными.
О том как работать с временными рядами (time series) в Postgresql, готовить данные для таблицы df и как строить графики мы поговорим в следующей статье.